RAG As A Service
What is Retrieval-Augmented Generation (RAG), and why is it important for Large Language Models (LLMs)?
Large language models (LLMs) have become the backbone of AI-powered applications, from virtual assistants to complex data analysis tools. However, despite their impressive capabilities, these models face limitations, particularly when it comes to providing up-to-date and accurate information. This is where Retrieval-Augmented Generation (RAG) comes into play, offering a powerful enhancement to LLMs.
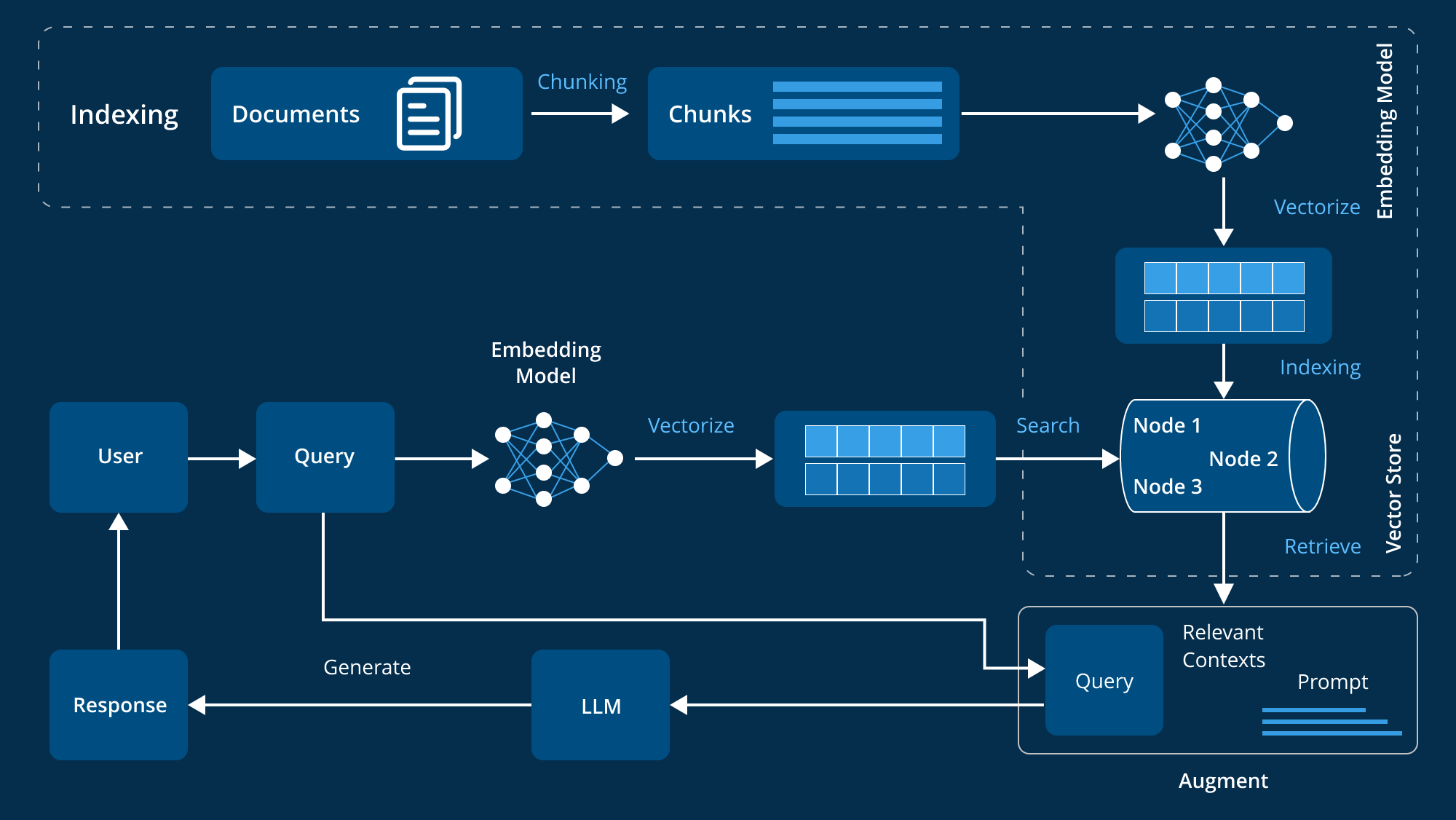
What is retrieval-augmented generation (RAG)?
Retrieval-augmented generation (RAG) is an advanced method used to enhance the performance of large language models (LLMs) by integrating external knowledge sources into their response generation process. LLMs, which are trained on extensive datasets and equipped with billions of parameters, are proficient in various tasks such as answering questions, translating languages, and completing sentences. However, RAG takes these capabilities a step further by referencing authoritative and domain-specific knowledge bases, thereby improving the relevance, accuracy, and utility of the generated responses without retraining the model. This cost-effective and efficient approach makes it an ideal solution for organizations looking to optimize their AI systems.
A RAG that actually works
Most Retrieval-Augmented Generation (AI RAG) demos impress because they connect a large language model to a small, carefully curated set of documents, producing smooth and convincing answers. Yet these prototypes hide major difficulties as soon as you leave the controlled environment of a demo. In an enterprise context, with massive volumes of heterogeneous documents, frequent updates, and multiple use cases, result quality drops, latency rises, and user trust erodes. The real problem is not model performance, but a data infrastructure unable to support operational complexity.
The failure of many production RAG systems often comes down to ingestion being treated as a one-time event rather than a continuous process. When the knowledge base evolves rapidly, a system fed with static data ends up delivering outdated answers, sometimes technically correct but mismatched with the current reality. At scale, these inaccuracies become systemic, perceived relevance declines, and security concerns, especially fine-grained access control, turn into major barriers to adoption.
RAG cannot be treated as a simple feature to bolt onto an existing application; it must be designed as a true infrastructure. Such an approach requires handling scale, format diversity, data governance, and regulatory constraints. The reliability of a production RAG system depends as much on the quality of generated answers as on the ability to guarantee source traceability, respect authorizations, and continuously monitor performance.
Building a robust RAG therefore requires a deep rethink of data processing: setting up continuous ingestion, ensuring preprocessing adapted to different formats (including complex documents), applying dynamic access controls at query time, and integrating re-ranking mechanisms to improve precision. When designed as an evolving infrastructure rather than a simple tech add-on, RAG can deliver reliable, secure, and durable answers, even in constantly changing environments.
Use Verbartim AI and get your own RAG
We act as a pure RAG As A Service, without any infrastructure. Try our service and get your own RAG for free for 90 days.
Frequently Asked Questions
Find answers to frequently asked questions about our service and technology
Ready to get your own AI Agent?
Let's take a few minutes to get to know each other and discuss your projects and needs.